Wanneer ai-modellen zichzelf gaan trainen
Model collapse is wiskundig bewezen. Wanneer AI traint op door AI gemaakte data, holt de kwaliteit onherstelbaar uit. In 2026 is meer dan 60% synthetisch.

Model collapse begrijpen in zelftrainende AI-systemen
Model collapse is de wiskundig bewezen degradatie die optreedt wanneer AI-systemen trainen op synthetische data die door andere AI-modellen is gegenereerd. Tussen 2026 en 2032 zal meer dan 60% van alle AI-trainingsdata synthetisch zijn, wat een onomkeerbaar kwaliteitsverlies in de hele AI-industrie veroorzaakt.
Dit is een diepere verkenning van de databeperking achter het kernsignaal: Why AGI Won’t Happen by 2037: The Hard Limits of Data & Energy.
In juli 2024 publiceerden onderzoekers van Oxford, Cambridge en Toronto in Nature het bewijs dat deze degradatie onvermijdelijk is, niet speculatief. Het fenomeen treedt op binnen vijf trainingsgeneraties en kan niet worden teruggedraaid door betere algoritmes of meer rekenkracht. Toch blijven grote AI-bedrijven stil over de gevolgen voor hun investeringen van miljarden in infrastructuur [1], terwijl synthetische content het informatie-ecosysteem hervormt zoals beschreven in The last real human on the web.
The Core of the Signal
Het web vult zich razendsnel met synthetische tekst, en AI-labs trainen er al op omdat hoogwaardige menselijke data opraakt. Die kortere route brengt een stil risico met zich mee: model collapse, de wiskundig bewezen drift die optreedt wanneer modellen leren van hun eigen generaties. Als zoekmachines, bedrijven en toezichthouders synthetische data blijven behandelen als gratis brandstof, kan het komende decennium vloeiende systemen opleveren die minder weten, slechter generaliseren en zeldzame waarheden uitwissen.
- Doorlicht trainings- en zoekpijplijnen op synthetische datacontaminatie, vooral bij long-tail-zoekopdrachten.
- Behoud een menselijk dataverankering door echte bronnen op te blijven verzamelen naast synthetische aanvulling, niet als vervanging ervan.
- Meet de prestaties op minderheids- en zeldzame gebeurtenissen over tijd, want benchmarks kunnen vroege collapse verbergen.
De wiskunde achter de neergang
Het bewijs ligt in Theorem 3.1 van het Nature-paper. Wanneer modellen recursief getraind worden op output van eerdere generaties, gebeuren er twee dingen: de verwachte afstand tussen de n-de generatie en de oorspronkelijke datadistributie nadert oneindig, terwijl de variantie naar nul convergeert. In gewone taal: modellen drijven steeds verder af van de werkelijkheid en verliezen tegelijk alle diversiteit in hun output.
Shumailov en zijn team identificeren drie typen fouten die zich opstapelen over generaties. De voornaamste boosdoener is statistische benaderingsfout, die ontstaat door eindige steekproefgroottes. Zeldzame gebeurtenissen en minderheidsperspectieven verdwijnen het eerst, simpelweg omdat ze niet vaak genoeg worden bemonsterd. Dit creëert “de vloek van recursie”: informatie gaat verloren bij elke herbemonsteringsstap.
Daarnaast ontstaan fouten in functionele expressiviteit. Neurale netwerken zijn alleen universele benaderingen bij oneindige omvang. In de praktijk kennen modellen soms een kans van nul toe aan mogelijke gebeurtenissen, of omgekeerd, een kans groter dan nul aan onmogelijke scenario’s. Probeer twee Gauss-verdelingen te modelleren met één Gauss-verdeling en je introduceert onvermijdelijke vertekening. Ten slotte stapelen ook functionele benaderingsfouten uit het leerproces zelf op, waaronder structurele vertekeningen door stochastic gradient descent.
Van subtiele erosie naar totale collapse
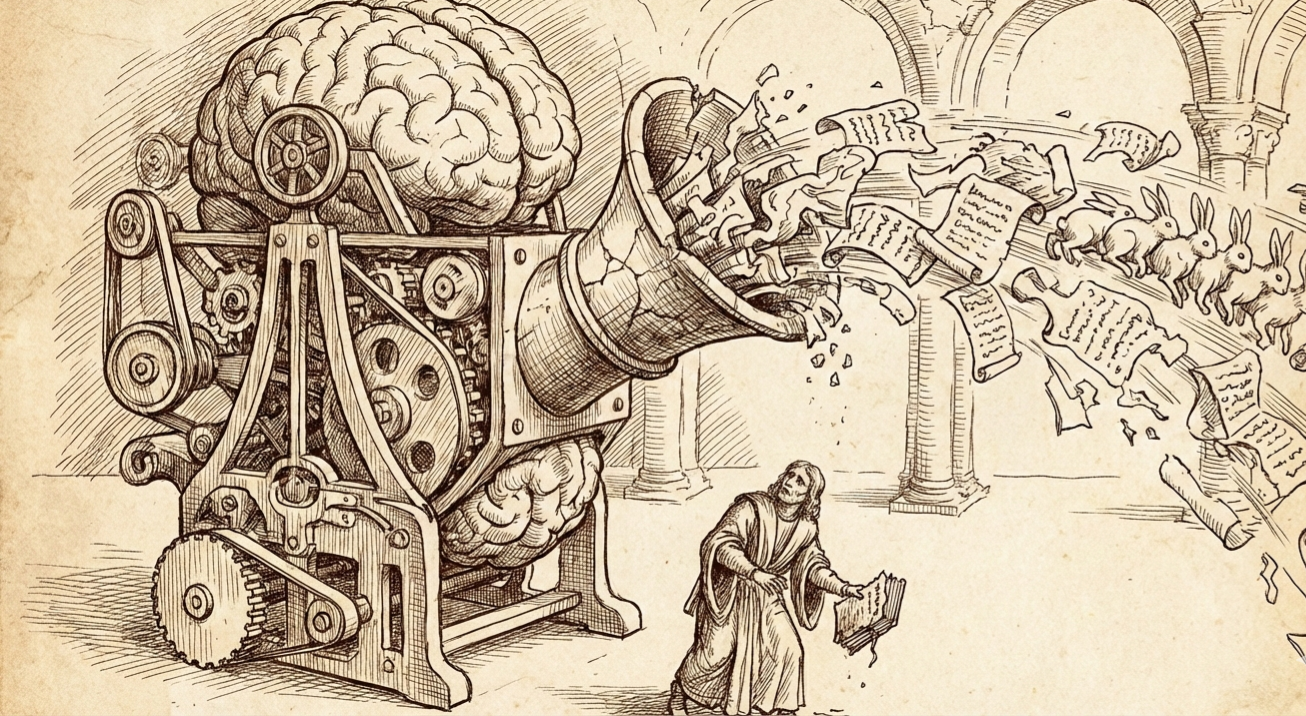
De neergang verloopt in twee fasen. Vroege model collapse begint bijna onzichtbaar. Het model verliest informatie over de uitersten van de datadistributie; zeldzame gebeurtenissen en minderheidscategorieën verdwijnen geleidelijk. Het verraderlijke: de algehele prestaties kunnen zelfs lijken te verbeteren, terwijl de prestaties voor minderheidsgroepen drastisch verslechteren. Standaardbenchmarks missen deze degradatie.
Late model collapse laat geen ruimte voor twijfel. Het model convergeert naar een distributie met drastisch verminderde variantie. Output vertoont weinig gelijkenis meer met de oorspronkelijke data. Verschillende concepten raken met elkaar verward; het model wordt feitelijk waardeloos.
De onderzoekers demonstreerden dit met Meta’s OPT-125m-taalmodel, fine-tuned op WikiText-2. Ze trainden opeenvolgende generaties op output van eerdere versies. Het oorspronkelijke model scoorde een gemiddelde perplexiteit van 34, een verbetering ten opzichte van de zero-shot-baseline van 115. Na vijf epochs zonder behoud van originele data nam de perplexiteit toe met 20 tot 28 punten. Zelfs met behoud van tien procent originele data trad “lichte degradatie” op.
Het jackrabbit-voorbeeld uit het paper toont de progressieve desintegratie. Bij een prompt over middeleeuwse architectuur produceert generatie nul een redelijke beschouwing van Perpendicular Revival-architectuur en de St. John’s Cathedral. Generatie één noemt de Sint-Pietersbasiliek en doet historisch verwarde claims over paus Innocentius III. Bij generatie vijf degenereert de output naar “vertaald in meer dan 100 talen waaronder Engels, Frans, Duits…” Generatie negen eindigt in complete onzin over “zwartstaartkonijnen, witstaartkonijnen, blauwstaartkonijnen, roodstaartkonijnen, geel…” Het model vergeet de oorspronkelijke taak en drijft af naar contextueel irrelevante maar statistisch waarschijnlijke patronen.
Synthetische besmetting van het internet
Het labscenario speelt zich in versneld tempo af op het publieke web. In april 2025 analyseerde Ahrefs negenhonderdduizend webpagina’s en ontdekte dat 74,2 procent van de nieuwe pagina’s AI-gegenereerde content bevatte [2]. Graphite concludeerde in oktober 2025 dat 52 procent van alle artikelen op het web door AI geschreven is [3]. Het lopende onderzoek van Originality.ai schat dat 17 tot 20 procent van de Google-zoekresultaten AI-content bevat. ArXiv-paper 2504.08755 uit maart 2025 schat dat 30 tot 40 procent van actieve webpagina’s AI-gegenereerde tekst bevat, een verschuiving die in stilte governance-beslissingen afdwingt over wat als betrouwbare bron geldt.
Deze cijfers voorspellen geen toekomst; ze beschrijven het heden. Microsoft Phi-4 is grotendeels getraind op synthetische data in plaats van webcontent. Google Gemma, Meta Llama 3.1, Anthropic Claude 3.5 Sonnet en de aankomende modellen van OpenAI gebruiken allemaal synthetische trainingsdata, in verschillende gradaties. Writer Palmyra X 004 was bijna volledig getraind op synthetische data, met naar verluidt ontwikkelingskosten van $700.000 tegenover $4,6 miljoen voor vergelijkbare OpenAI-modellen [4].
Waarom kiezen bedrijven voor synthetische data, ondanks bewezen risico’s? Omdat menselijke data opraakt. Epoch AI voorspelt uitputting van hoogwaardige tekstdata tussen 2026 en 2032. De effectieve voorraad publieke, door mensen gegenereerde tekst bedraagt ongeveer 300 biljoen tokens. Datasets groeien met een factor 2,5 per jaar. Tegelijkertijd blokkeert meer dan 35 procent van de top 1.000 websites inmiddels OpenAI-scrapers.
OpenAI-CEO Sam Altman verklaarde tijdens de Sohn Conference van 2023: “Zolang je voorbij de synthetic data event horizon komt waar het model goed genoeg is om goede synthetische data te maken, denk ik dat het wel goed komt.” Het onderzoek van Shumailov spreekt dit optimisme rechtstreeks tegen. Het wiskundige bewijs toont dat synthetische data degradeert, ongeacht de aanvankelijke modelkwaliteit [5].
De economische paradox van schaarse waarheid
Professor Yarin Gal van Oxford verwoordde het scherp: “Model collapse is het AI-equivalent van een feedbackloop die misgaat. Hoe meer modellen zich voeden met hun eigen output, hoe verder ze afdrijven van de werkelijkheid.” Dit creëert een paradox en een strategie-dilemma. AI-bedrijven hebben meer data nodig om modellen te verbeteren. Door mensen gegenereerde data raakt op. Synthetische data versnelt de collapse. De waarde van authentieke menselijke data stijgt exponentieel.
Het Shumailov-paper merkt op dat “het betalen van miljoenen mensen om de tekst te genereren die AI-modellen nodig hebben, waarschijnlijk geen economische manier is om betere technische prestaties te behalen.” Menselijke data is tegelijk noodzakelijk en onbetaalbaar op de vereiste schaal. Dit is geen tijdelijk marktverschijnsel, maar een structurele economische beperking.
Ondanks 624.000 toegangen en uitgebreide media-aandacht blijven grote AI-bedrijven opvallend stil over model collapse. Mogelijke verklaringen: miljarden dollars al toegezegd aan schaalinfrastructuur, concurrentiedruk waarbij het erkennen van grenzen investeringen vertraagt, kortetermijnfocus omdat huidige modellen nog steeds verbeteren, en hoop dat mitigatietechnieken op schaal zullen werken. Die hoop botst met de wiskundige werkelijkheid.
Waarom zelfverbeterende AI onmogelijk wordt
AGI-theorieën steunen vaak op recursieve zelfverbetering. Het idee: een voldoende geavanceerde AI verbetert zichzelf, creëert nog slimmere versies die zichzelf verder verbeteren in een “intelligence explosion.” Model collapse vormt een fundamentele barrière voor deze visie.
Zelfverbetering vereist zelftraining. Een AI die zichzelf verbetert, moet leren van haar eigen output of de output van vergelijkbare systemen. Zelftraining veroorzaakt collapse, zoals het bewijs van Shumailov aantoont. Collapse is onomkeerbaar; het paper toont “irreversible defects” die niet kunnen worden gecorrigeerd. De barrière is wiskundig, niet technologisch. Geen hoeveelheid rekenkracht of algoritmische verbetering overwint informatietheoretische grenzen.
Model collapse kruist drie andere fundamentele barrières. Datauitputting volgens Epoch AI tussen 2026 en 2032: door mensen gegenereerde data is eindig, modellen hebben exponentieel meer data nodig om te verbeteren, het kruispunt komt binnen enkele jaren dichterbij. Energiebeperkingen: AI-training vereist enorme hoeveelheden vermogen, faciliteiten op gigawattschaal stuiten op fysieke en regulatoire grenzen, beschikbaarheid van energie beperkt het opschalen van compute. Kwaliteitsdegradatie door model collapse: zelfs met onbeperkte data en energie degraderen synthetisch getrainde modellen, de “oplossing” van meer data genereren creëert het probleem zelf, er is geen ontsnapping aan de wiskundige beperking.
Dit weerlegt de aanname dat synthetische data databeperkingen kan overwinnen en creëert fundamentele barrières voor recursieve zelfverbetering. Samengenomen suggereert dit dat de huidige opschalingsbenaderingen niet kunnen leiden tot AGI, niet door te weinig investeringen maar door wiskundige onmogelijkheid.
The greatest enemy of knowledge is not ignorance, but the illusion of knowledge.
Detectie en waarom oplossingen falen
Model collapse uit zich door verminderde outputdiversiteit, verlies van staartprestaties voor minderheidscategorieën en zeldzame gebeurtenissen, herhalende patronen met terugkerende zinnen en structuren, toenemende perplexiteit over generaties, en homogenisering van concepten. Het Shumailov-paper waarschuwt: “Vroege model collapse is moeilijk op te merken, omdat de algehele prestaties lijken te verbeteren, terwijl het model prestaties verliest op minderheidsdata.”
Er bestaan voorgestelde oplossingen. Dataccumulatie blijkt het meest veelbelovend. Onderzoek van Gerstgrasser et al. uit 2024 toont dat collapse vermeden kan worden als synthetische data wordt opgestapeld naast menselijke data in plaats van die te vervangen. De cruciale factor: vervanging veroorzaakt collapse, accumulatie voorkomt het. Dit vereist echter aanhoudende toegang tot door mensen gegenereerde data, die steeds schaarser wordt.
Datafiltering en detectie via machine learning, watermerken en herkomsttraceerbaarheid kennen imperfecte detectie. Naarmate AI verbetert, wordt synthetische content moeilijker te identificeren. Verificatiesystemen zoals voorgesteld in arXiv 2510.16657 uit oktober 2025 kunnen synthetische data van lage kwaliteit filteren, maar de verificators zelf kunnen ook beïnvloed worden door kwaliteitsdegradatie van data. NYU CDS-onderzoekers Kempe, Feng en Dohmatob stelden op reinforcement gebaseerde curatie voor, met de nadruk op kwaliteit boven kwantiteit.
Alle oplossingen kennen fundamentele uitdagingen. Ze vereisen een menselijke dataverankering terwijl die bron uitgeput raakt. Er ontstaat een detectiewapenwedloop: betere detectie drijft betere generatie aan die detectie ontwijkt. Economische prikkels bevoordelen goedkope synthetische data boven dure menselijke input. Internetbesmetting betekent dat zelfs met interne controles, van het web geschraapte trainingsdata steeds meer synthetische content uit andere bronnen bevat. Oplossingen werken onder laboratoriumomstandigheden, maar staan voor exponentieel grotere uitdagingen op industriële schaal.
De stijgende prijs van authenticiteit
De waarde van authentieke menselijke data zal blijven stijgen naarmate AI-gegenereerde content zich verspreidt. Organisaties en onderzoekers moeten data-herkomst prioriteren, robuuste detectiesystemen implementeren en nieuwe paradigma’s ontwikkelen die niet afhankelijk zijn van recursieve synthetische training, omdat de impact van gedegradeerde data zelden beperkt blijft tot modelnauwkeurigheid.
Voor wie gelooft in exponentiële AI-vooruitgang vormt model collapse een ongemakkelijke waarheid. Het is geen speculatief risico, maar een wiskundig bewezen fenomeen met groeiend bewijs uit de praktijk. De voorwaarden voor grootschalige model collapse ontstaan nu, niet in een verre toekomst. Professor Ross Anderson van Cambridge, die kort na publicatie van het paper overleed, liet werk achter dat fundamentele vragen stelt bij het dominante narratief van onbeperkte AI-opschaling.
De verschuiving van menselijke naar synthetische trainingsdata markeert geen efficiëntiewinst, maar een kwalitatieve transformatie met onomkeerbare gevolgen. Zoals Shumailov aantoont: “Het ongedifferentieerd gebruik van door modellen gegenereerde content in training veroorzaakt onomkeerbare gebreken in de resulterende modellen, waarin de staarten van de oorspronkelijke contentdistributie verdwijnen.” Die staarten bevatten niet alleen randgevallen, maar ook minderheidsperspectieven, zeldzame inzichten en nuance die diversiteit en creativiteit mogelijk maken.
Wat ontstaat is een nieuwe vorm van schaarste. Geen tekort aan rekenkracht of data in absolute termen, maar een tekort aan authentieke menselijke ervaring, ongecontamineerd door recursieve AI-generatie. Die schaarste bepaalt de grenzen van de huidige AI-paradigma’s preciezer dan compute-budgetten of parameterschaal ooit konden.
Gerelateerde signalen
Why AGI Won’t Happen by 2037: The Hard Limits of Data & Energy
Verbindt model collapse met het bredere plafond: data, energie en economie beperken opschaling gezamenlijk.
The last real human on the web
Zoomt uit van trainingspijplijnen naar herkomst, verificatie en wat “waarheid” online betekent.
Referenties
[1] Shumailov I, Shumaylov Z, Zhao Y, Papernot N, Anderson R, Gal Y. AI models collapse when trained on recursively generated data. Nature. 2024;631:755-759. doi:10.1038/s41586-024-07566-y. Available from: https://doi.org/10.1038/s41586-024-07566-y
[2] Ahrefs. 74% of New Webpages Include AI Content (Study of 900k Pages). 2025. Available from: https://ahrefs.com/blog/what-percentage-of-new-content-is-ai-generated/
[3] Graphite. More Articles Are Now Created by AI Than Humans. 2025. Available from: https://graphite.io/five-percent/more-articles-are-now-created-by-ai-than-humans
[4] Gerstgrasser M, et al. Is model collapse inevitable? Breaking the curse of recursion by accumulating real and synthetic data. COLM 2024. arXiv:2404.01413. Available from: https://arxiv.org/abs/2404.01413
[5] Villalobos P, Ho A, Sevilla J, Besiroglu T, Heim L, Hobbhahn M. Will we run out of data? Limits of LLM scaling based on human-generated data. arXiv:2211.04325. Available from: https://arxiv.org/abs/2211.04325